Mysterious Corpse-voice: STT-TTS Voice Explorations
Interaction Flow of Mysterious Corpse: Speech to text, text to speech
Challenge: Adaptation of a previous web project (see below) I built (see below) to incorporate voice technology.
How to highlight similarities and differences in language of particular authors' styles within the Mystery genre, and engage potential readers with a taste of those styles, while experimenting with, and learning about, voice technologies. I iterated from my original application, Mysterious Corpse-Web (see below) to create Mysterious Corpse-Voice.
Approach: Mysterious Corpse-Voice, was an experiment in speech recognition and speech-to-text capabilities; I also wanted to learn about using the Asterisk VOIP capability. I thought it could be interesting to appeal to potential readers with voice excerpts that could entice them to read the texts they heard read--though, in the future, using better voice than the robotic ones available in this first iteration of the project.
Role: Sole creator - Sinatra/Ruby programming, Google STT & TTS, Asterisk dialplan, Visual design.
Tools: Sinatra/Ruby, Datamapper, HTML/CSS, Asterisk (IVR), Google TTS/STT
On Mysterious Corpse-Voice: Sole creator - Sinatra/Ruby, Asterisk Dialplan, Google Text-to-Speech & Speech-to-text, Flowroute phone
https://github.com/dcm858/Mysterious-Corpse-TTS-STT-Asterisk-Version
FIRST REVISION OF USER EXPERIENCE
Though Mysterious Corpse-Voice was never meant to be an exercise in beautiful visual design, I found, as I approached the end of work on the basic application, that people might enjoy the application more if I provided a minimal visual to display their choices as they made them, adding each as it was made, and resulting in a graphic of three icons, describing each of the three criteria.
I wrestled with the possibility of showing the text of the mashed-up sentence speech being spoken by the application on the phone screen, after this visual displayed, but I wanted to keep the user experience’s emphasis on the audio element, and adding a text read-out would mean that I was making it a hybrid screen-speech app.
In creating this version of Mysterious Corpse using Text-to-Speech, Speech-to-Text, and the Asterisk Voice-over-IP server, I made many adjustments to accommodate the user experience using voice, and learned a bit about the kind of adjustments that often need to be made to correct text-to-speech interpretation and vocalization.
The Actions The action is basic voice recognition and text-to-speech rendering as a result right now:
(1) Dial the number
(2) The caller is greeted, and is asked to speak his/her choice from four mystery genre options: legal, "dark"*, satirical, political
(3) The caller speaks his/her choice of setting: US or non-US
(4) The caller chooses a male or female protagonist.
(5) The caller hears a spoken mash-up of a couple of sentences meeting the selected criteria.
User Testing Surfaced Necessary Adjustments to Mis-Recognized Speech
This was surprising to me, since the STT capability seemed to have no trouble correctly recognizing the similar-sounding words "satirical" and "political." In my first design iteration, I had wanted to offer the user numbers that corresponded to the various selection criteria. I thought that the numbers would be easier for Google STT than multi-syllabic words to recognize, but the user experience felt clunky, and I still got errors in recognition. In the test shown in the video below, I shortened one of the sentences in the database, to test how the length of a sentence might affect the speech rendering of the text. As such, I found that having users respond directly, to repeat an option choice, was no harder for STT to recognize, and was a cleaner interaction flow.

Frequently-mis-recognized words/phrases in Mysterious Corpse's Voice Version
• Initially, selecting “non-US” as the MysteriousCorpse location rendered as “non-us” and so prevents a further flow since "non-us" is not recognized in database.
• Pronouncing “female” with too much “fvvv” rendered as “shemale”– a new variation to add to the other erroneous pronunciation recognitions I got in Google STT's hearing of “female”.
• “Male” more often than not was rendered as its homophone, “mail” which affected adversely the result since the database spells “male” as “male”. I changed the .yml file so that it recognizes both.
• “US” was often recognized as “you-off”
• “Political” was recognized correctly twice in a row, and “satirical” was also rendered correctly.
• The sub-genre “Noir” was frequently mis-recognized, regardless of how clearly and explicitly it was pronounced in testing. In the final version of the text-to-speech script, I changed the name of the "Noir" sub-genre of mystery to "Dark," which STT recognized correctly and consistently.
The code sample provided here illustrates the flow of interaction from initial answering of a VOIP call (via the VOIP provider Flowroute) through the greeting, the mystery criteria choices and response, and the final successful retrieval of the mashup of these choices (used in the test video above), text recognition and speaking of the choices back to the caller.
[* I changed the "noir" genre selection to "dark", against my better literary and critical instincts, because the Google speech recognition over the phone repeatedly mis-recognized "noir" as "-------"]
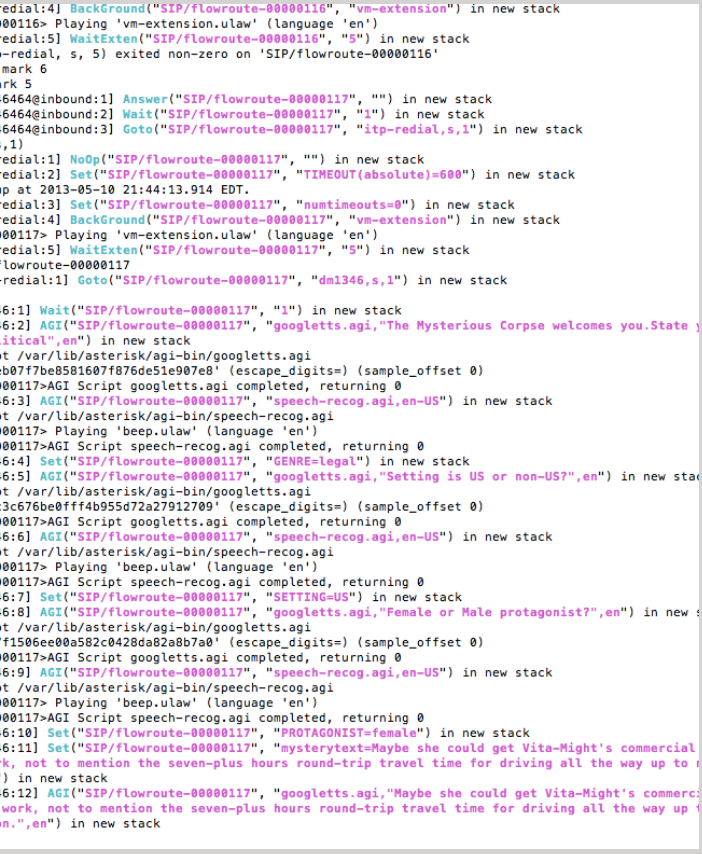
Flow Log of Speech/Text from Asterisk Server with Google TTS/STT to Phone via Flowroute
Final Testing - Mysterious Corpse - Phone
mysterious corpse - Web
Using the first and second sentences of various mystery novel favorites, along with others I chose with the help of Amazon's "Look Inside" I created a YAML file for storage and used the Sinatra Ruby framework to combine the sentences based on a few criteria.
Additionally, I included features that enabled adding and deleting of mystery titles, sentences, and their associated information from the YAML file. These features were accessible to all users, as I had in mind, in the moment I created it, a kind of "community" Mysterious Corpse. However, I was aware that such openness would require oversight.
A future iteration, to create a "group-corpse" functionality, allowing groups of people to create mysterious corpses of greater length, while adding to the database of texts.
Challenge: How to highlight similarities and differences in the language of authors' styles within a particular genre, and engage potential readers with a taste of those styles?
Role: Sole creator - All work on Mysterious Corpse - Ideation, Sinatra/Ruby programming, YAML file creation, interaction, interface & visual design.
https://github.com/dcm858/mysterious-corpse-first
Process: For Mysterious Corpse - I designed a simple form using the Courier font and an additional font that had a 1930s-look to it, to establish a mood of mystery novels written on typewriters, in the heyday of mystery writers such as Chandler, Sayers and Hammett.
I created a path from my Sinatra script to the YAML file, where I picked up sentences by a user's selected criteria and returned them to a second screen, with the origin of the individual pieces of "mashed-up" content identified. See below for further details.
For Mysterious Corpse-Voice - See above for full details.
Tools: Sinatra/Ruby, Datamapper, HTML/CSS,
Approach: I used a text mash-up: Almost everyone is familiar with the Surrealists' "Exquisite Corpse," as well as the popularized version of the same idea, "MadLibs." With these mash-ups as examples, I wanted to create something that could entertain people with surprising combinations, while exposing different snippets of writing, their similarlities and differences, within sub-genres of the broad genre of "Mystery."
I incorporated a voice capability a few months later not only to experiment with what was a new medium for me, but because I think that spoken text, even when spoken by a robotic, uninflected or strangely-inflected voice, commands more attention than text read silently.